Street Population Density#
In the last two notebooks, we worked on how to determine the population of any given area using the raster dataset GHS-POP (Global Human Settlement Population Layer) for the P2023 release[1]. As our goal is to repeatedly determine the population density of Superblocks, we want to have an effective way to do this. As the Superblocks are made up of subgraphs of our road network, we showed a way to tessellate using roads.
/tmp/ipykernel_3402/1961901240.py:10: DeprecationWarning: `scipy.odr` is deprecated as of version 1.17.0 and will be removed in SciPy 1.19.0. Please use `https://pypi.org/project/odrpack/` instead.
from scipy.odr import ODR, Model, RealData
2026-03-23 16:18:06,461 | INFO | __init__.py:11 | superblockify version 1.0.2
Voronoi Tessellation#
We can use a Voronoi tessellation to divide up the area around a given node into cells. This looks like the following:
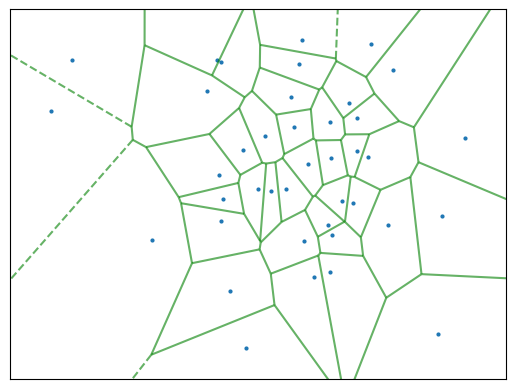
To keep the code effective, we renounce calculating the Voronoi tessellation for each partition of the road network. Instead, tessellate the whole road network once using roads and calculate the population and area of each road cell. Then, we can use this information to determine the population density of each Superblock repeatedly. More on the edge tesselation in the previous chapter Street Tessellation.
There are two approaches we want to consider integrating the population raster data over the road cells. The first approach is to use up-sampled raster data, as we did before. The second approach is to polygonize the raster data and intersect the road cells with it. For both, we need to consider used memory and computation time. Loading in a big city with an up-sampled raster dataset can take a lot of time and memory, but it needs to be up-sampled to reach better population approximations. Calculating intersections between polygons could be computationally heavy.
Data Preparation#
First, let’s get an example road network and tessellate it. We are Using La Crosse, Wisconsin as an example. By the Native American Neshnabé/Potawatomi, it is called ensewaksak. The working CRS is the World Mollweide projection, as it is an equal-area projection, and the GHS-POP raster data is in this projection. But the edge cells need to be calculated in the local CRS, to avoid distortion.
lc_graph = ox.graph_from_place("La Crosse, La Crosse County, Wisconsin, United "
"States",
network_type="drive")
lc_graph = ox.project_graph(lc_graph) # to local UTM zone
# Get Road Cells
lc_road_cells = get_edge_cells(lc_graph)
# Project to World Mollweide
lc_road_cells = lc_road_cells.to_crs("World Mollweide")
2026-03-23 16:19:16,319 | INFO | tessellation.py:101 | Calculating edge cells for graph with 4846 edges.
2026-03-23 16:19:22,828 | INFO | tessellation.py:155 | Tessellated 2667 edge cells in 0:00:06.
How does the tessellation look like?
# random color of CSS4_COLORS
lc_road_cells["color_name"] = np.random.choice(list(CSS4_COLORS.keys()),
size=len(lc_road_cells))
lc_road_cells.explore(color="color_name", style_kwds={"color": "black", "opacity": 0.5,
"weight": 1}, zoom_start=14)
We need to get the GHS-POP raster data for the area of interest. For that we can
use the get_ghsl function from the superblockify package. It needs a bounding box
of the whole are in Mollweide projection, and it will download the raster data and
return the file path(s) to the raster data. The raster data is in GeoTIFF format.
For that, we take the union of all road cells and get the bounding box of it. When
looking at the union, the skewness of our projection is visible.
lc_road_cells.union_all()

lc_bbox = lc_road_cells.union_all().bounds
lc_ghsl = get_ghsl(lc_bbox)
2026-03-23 16:19:25,257 | INFO | ghsl.py:129 | Using the GHSL raster tiles for the bounding box (-7466813.832850865, 5203806.837155395, -7458947.843992426, 5217155.90905567).
Up-sampled Raster Data#
Try to load the raster data inside the bounding box into memory and scale up by a
factor of 10. The original cells are 100m x 100m, so the up-sampled cells are 10m x 10m.
For that, we use the resample_load_window function from the superblockify package.
lc_ghsl_upsampled, lc_affine_upsampled = resample_load_window(
file=lc_ghsl, resample_factor=10, window=lc_road_cells)
lc_ghsl_upsampled /= 10 ** 2
The resampling strategy for upscaling is nearest, so to conserve the population
values, we needed to divide the population values by the resample factor squared.
Now, we can use the zonal_stats function from the rasterstats package to calculate
the population and area of each road cell. Just like we did in the Population Density
notebook.
lc_zonal_stats = zonal_stats(lc_road_cells, lc_ghsl_upsampled,
affine=lc_affine_upsampled,
stats=["sum"], nodata=0, all_touched=False)
lc_zonal_stats
To visualize, we will write this to the lc_road_cells GeoDataFrame.
# Write to lc_road_cells
lc_road_cells["population_sampled_10"] = [zs_cell["sum"] for zs_cell in lc_zonal_stats]
# pop density in people per square meter
lc_road_cells["pop_density_sampled_10"] = lc_road_cells["population_sampled_10"] / \
lc_road_cells["geometry"].area
# Plot with colormap
lc_road_cells.explore(column="pop_density_sampled_10", zoom_start=14)
Here we also see cells with a population density of 0. This is the case on Barron Island in the Mississippi River, as it should, or industrial areas. For especially small cells, the uncertainty introduced by the raster is higher in comparison to the absolute population. This effect might be visible here, when specifically looking at the cells, but when dissolving the cells into Superblocks, the effect will compensate itself.
Polygonized Raster Data#
For this approach first, we need to polygonize the raster data. For that, rasterio
has the features.shapes function.
Then we will use a shapely.STRtree to intersect the road cells with
the polygons. The shapely.STRtree is a spatial index, which can be used to
efficiently query the intersection of two geometries. From the tesselation we will
build up the spatial index and query the intersection of the road cells with the
polygons. This way we will distribute the population of the raster to the road cells,
weighted by the intersecting fraction.
# raster, no upsample
lc_ghsl_unsampled, lc_affine_unsampled = resample_load_window(file=lc_ghsl,
window=lc_road_cells)
# convert to float32
lc_ghsl_unsampled = lc_ghsl_unsampled.astype(np.float32)
lc_shapes = [
{'population': pop, 'geometry': shp}
for _, (shp, pop) in enumerate(shapes(lc_ghsl_unsampled,
transform=lc_affine_unsampled))
if pop > 0
]
lc_ghsl_polygons = gpd.GeoDataFrame(
geometry=[shape(geom["geometry"]) for geom in lc_shapes],
data=[geom["population"] for geom in lc_shapes],
columns=["population"],
crs="World Mollweide"
)
lc_ghsl_polygons.explore(column="population", vmax=260)
One cell has a population of over 500 people; this is why we set the cutoff to 260. Looking at the cell on a map, a number this high is implausible. For our analysis, we could provide a sanity-check, where one can set a cutoff. But other than that ,this is a problem of the GHS-POP data. In general, the data quality of the GHS-POP dataset is very high and well suited for our evaluation, in spite of this outlier.
Let us build up the spatial index of the tesselation.
lc_road_cells_sindex = STRtree(lc_road_cells.geometry)
# Distributing the population over the road cells
# initialize population column
lc_road_cells["population_polygons"] = 0
# Query all geometries at once lc_road_cells_sindex.query(lc_ghsl_polygons["geometry"])
lc_road_cells_loc_pop = lc_road_cells.columns.get_loc("population_polygons")
for pop_cell_idx, road_cell_idx in lc_road_cells_sindex.query(
lc_ghsl_polygons["geometry"]).T:
# get the intersection of the road cell and the polygon
intersection = lc_road_cells.iloc[road_cell_idx]["geometry"].intersection(
lc_ghsl_polygons.iloc[pop_cell_idx]["geometry"]
)
population = lc_ghsl_polygons.iloc[pop_cell_idx]["population"]
# query by row number of lc_road_cells, as lc_road_cells has different index
lc_road_cells.iat[
road_cell_idx, lc_road_cells_loc_pop] += population * intersection.area / \
lc_ghsl_polygons.iloc[pop_cell_idx][
"geometry"].area
lc_road_cells["population_polygons"]
---------------------------------------------------------------------------
LossySetitemError Traceback (most recent call last)
File ~/micromamba/envs/sb_env/lib/python3.12/site-packages/pandas/core/frame.py:4911, in DataFrame._set_value(self, index, col, value, takeable)
4910 iindex = self.index.get_loc(index)
-> 4911 self._mgr.column_setitem(icol, iindex, value, inplace_only=True)
4913 except (KeyError, TypeError, ValueError, LossySetitemError):
4914 # get_loc might raise a KeyError for missing labels (falling back
4915 # to (i)loc will do expansion of the index)
4916 # column_setitem will do validation that may raise TypeError,
4917 # ValueError, or LossySetitemError
4918 # set using a non-recursive method & reset the cache
File ~/micromamba/envs/sb_env/lib/python3.12/site-packages/pandas/core/internals/managers.py:1518, in BlockManager.column_setitem(self, loc, idx, value, inplace_only)
1517 if inplace_only:
-> 1518 col_mgr.setitem_inplace(idx, value)
1519 else:
File ~/micromamba/envs/sb_env/lib/python3.12/site-packages/pandas/core/internals/managers.py:2220, in SingleBlockManager.setitem_inplace(self, indexer, value)
2217 if isinstance(arr, np.ndarray):
2218 # Note: checking for ndarray instead of np.dtype means we exclude
2219 # dt64/td64, which do their own validation.
-> 2220 value = np_can_hold_element(arr.dtype, value)
2222 if isinstance(value, np.ndarray) and value.ndim == 1 and len(value) == 1:
2223 # NumPy 1.25 deprecation: https://github.com/numpy/numpy/pull/10615
File ~/micromamba/envs/sb_env/lib/python3.12/site-packages/pandas/core/dtypes/cast.py:1725, in np_can_hold_element(dtype, element)
1724 # Anything other than integer we cannot hold
-> 1725 raise LossySetitemError
1726 if (
1727 dtype.kind == "u"
1728 and isinstance(element, np.ndarray)
1729 and element.dtype.kind == "i"
1730 ):
1731 # see test_where_uint64
LossySetitemError:
During handling of the above exception, another exception occurred:
LossySetitemError Traceback (most recent call last)
File ~/micromamba/envs/sb_env/lib/python3.12/site-packages/pandas/core/internals/blocks.py:1115, in Block.setitem(self, indexer, value)
1114 try:
-> 1115 casted = np_can_hold_element(values.dtype, value)
1116 except LossySetitemError:
1117 # current dtype cannot store value, coerce to common dtype
File ~/micromamba/envs/sb_env/lib/python3.12/site-packages/pandas/core/dtypes/cast.py:1725, in np_can_hold_element(dtype, element)
1724 # Anything other than integer we cannot hold
-> 1725 raise LossySetitemError
1726 if (
1727 dtype.kind == "u"
1728 and isinstance(element, np.ndarray)
1729 and element.dtype.kind == "i"
1730 ):
1731 # see test_where_uint64
LossySetitemError:
During handling of the above exception, another exception occurred:
TypeError Traceback (most recent call last)
Cell In[12], line 15
13 population = lc_ghsl_polygons.iloc[pop_cell_idx]["population"]
14 # query by row number of lc_road_cells, as lc_road_cells has different index
---> 15 lc_road_cells.iat[
16 road_cell_idx, lc_road_cells_loc_pop] += population * intersection.area / \
17 lc_ghsl_polygons.iloc[pop_cell_idx][
18 "geometry"].area
19 lc_road_cells["population_polygons"]
File ~/micromamba/envs/sb_env/lib/python3.12/site-packages/pandas/core/indexing.py:2615, in _iAtIndexer.__setitem__(self, key, value)
2610 if sys.getrefcount(self.obj) <= REF_COUNT_IDX:
2611 warnings.warn(
2612 _chained_assignment_msg, ChainedAssignmentError, stacklevel=2
2613 )
-> 2615 return super().__setitem__(key, value)
File ~/micromamba/envs/sb_env/lib/python3.12/site-packages/pandas/core/indexing.py:2542, in _ScalarAccessIndexer.__setitem__(self, key, value)
2539 if len(key) != self.ndim:
2540 raise ValueError("Not enough indexers for scalar access (setting)!")
-> 2542 self.obj._set_value(*key, value=value, takeable=self._takeable)
File ~/micromamba/envs/sb_env/lib/python3.12/site-packages/pandas/core/frame.py:4920, in DataFrame._set_value(self, index, col, value, takeable)
4913 except (KeyError, TypeError, ValueError, LossySetitemError):
4914 # get_loc might raise a KeyError for missing labels (falling back
4915 # to (i)loc will do expansion of the index)
4916 # column_setitem will do validation that may raise TypeError,
4917 # ValueError, or LossySetitemError
4918 # set using a non-recursive method & reset the cache
4919 if takeable:
-> 4920 self.iloc[index, col] = value
4921 else:
4922 self.loc[index, col] = value
File ~/micromamba/envs/sb_env/lib/python3.12/site-packages/pandas/core/indexing.py:938, in _LocationIndexer.__setitem__(self, key, value)
933 self._has_valid_setitem_indexer(key)
935 iloc: _iLocIndexer = (
936 cast("_iLocIndexer", self) if self.name == "iloc" else self.obj.iloc
937 )
--> 938 iloc._setitem_with_indexer(indexer, value, self.name)
File ~/micromamba/envs/sb_env/lib/python3.12/site-packages/pandas/core/indexing.py:1953, in _iLocIndexer._setitem_with_indexer(self, indexer, value, name)
1950 # align and set the values
1951 if take_split_path:
1952 # We have to operate column-wise
-> 1953 self._setitem_with_indexer_split_path(indexer, value, name)
1954 else:
1955 self._setitem_single_block(indexer, value, name)
File ~/micromamba/envs/sb_env/lib/python3.12/site-packages/pandas/core/indexing.py:2044, in _iLocIndexer._setitem_with_indexer_split_path(self, indexer, value, name)
2041 else:
2042 # scalar value
2043 for loc in ilocs:
-> 2044 self._setitem_single_column(loc, value, pi)
File ~/micromamba/envs/sb_env/lib/python3.12/site-packages/pandas/core/indexing.py:2181, in _iLocIndexer._setitem_single_column(self, loc, value, plane_indexer)
2171 if dtype == np.void:
2172 # This means we're expanding, with multiple columns, e.g.
2173 # df = pd.DataFrame({'A': [1,2,3], 'B': [4,5,6]})
(...) 2176 # Here, we replace those temporary `np.void` columns with
2177 # columns of the appropriate dtype, based on `value`.
2178 self.obj.iloc[:, loc] = construct_1d_array_from_inferred_fill_value(
2179 value, len(self.obj)
2180 )
-> 2181 self.obj._mgr.column_setitem(loc, plane_indexer, value)
File ~/micromamba/envs/sb_env/lib/python3.12/site-packages/pandas/core/internals/managers.py:1520, in BlockManager.column_setitem(self, loc, idx, value, inplace_only)
1518 col_mgr.setitem_inplace(idx, value)
1519 else:
-> 1520 new_mgr = col_mgr.setitem((idx,), value)
1521 self.iset(loc, new_mgr._block.values, inplace=True)
File ~/micromamba/envs/sb_env/lib/python3.12/site-packages/pandas/core/internals/managers.py:604, in BaseBlockManager.setitem(self, indexer, value)
600 # No need to split if we either set all columns or on a single block
601 # manager
602 self = self.copy(deep=True)
--> 604 return self.apply("setitem", indexer=indexer, value=value)
File ~/micromamba/envs/sb_env/lib/python3.12/site-packages/pandas/core/internals/managers.py:442, in BaseBlockManager.apply(self, f, align_keys, **kwargs)
440 applied = b.apply(f, **kwargs)
441 else:
--> 442 applied = getattr(b, f)(**kwargs)
443 result_blocks = extend_blocks(applied, result_blocks)
445 out = type(self).from_blocks(result_blocks, [ax.view() for ax in self.axes])
File ~/micromamba/envs/sb_env/lib/python3.12/site-packages/pandas/core/internals/blocks.py:1118, in Block.setitem(self, indexer, value)
1115 casted = np_can_hold_element(values.dtype, value)
1116 except LossySetitemError:
1117 # current dtype cannot store value, coerce to common dtype
-> 1118 nb = self.coerce_to_target_dtype(value, raise_on_upcast=True)
1119 return nb.setitem(indexer, value)
1120 else:
File ~/micromamba/envs/sb_env/lib/python3.12/site-packages/pandas/core/internals/blocks.py:468, in Block.coerce_to_target_dtype(self, other, raise_on_upcast)
465 raise_on_upcast = False
467 if raise_on_upcast:
--> 468 raise TypeError(f"Invalid value '{other}' for dtype '{self.values.dtype}'")
469 if self.values.dtype == new_dtype:
470 raise AssertionError(
471 f"Did not expect new dtype {new_dtype} to equal self.dtype "
472 f"{self.values.dtype}. Please report a bug at "
473 "https://github.com/pandas-dev/pandas/issues."
474 )
TypeError: Invalid value '0.5128727600374337' for dtype 'int64'
Let us look at this again on a map.
# pop density in people per square meter
lc_road_cells["pop_density_polygons"] = lc_road_cells["population_polygons"] / \
lc_road_cells["geometry"].area
# Plot with colormap
lc_road_cells.explore(column="pop_density_polygons", zoom_start=14)
Uncertainty Estimation#
The GHSL datasheet does not give an explicit error estimation for the population values. However, it gives expected errors of the new GHS-BUILT-S R2023A release at 10m for the various area types, see Table 6 in the report[1]. For the urban and built up areas the RMSE (root mean square error) is \(0.296\) and the MAPE (mean absolute percentage error) is \(0.218\). Because the population data is inferred from this data, we can assume the error is of the same magnitude. As the used GHS-POP data we use has a lower resolution, we estimate the error for our 100m x 100m cells is lower. For each population cell, we estimate the uncertainty by a symmetric triangle distribution of the width \(p\cdot \mathrm{MAPE}_\mathrm{urban}\), where \(p\) is the population of each raster cell. From this we get a standard deviation of \(u(p) = \frac{p\cdot \mathrm{MAPE}_\mathrm{urban}}{\sqrt{6}}\) [2].
For Poland and Portugal case studies Calka and Bielecka estimate MAPEs from 1.0% to 5.71% for the 250m resolution of th 2019 data[3], while Kuffer et al. stress that overestimation in low-density or sparsely populated outskirts of cities can be even bigger. Underestimation can happen for high-density residential areas. Crucial is also, there is no one accepted standard for the uncertainty estimation of population data [4]. This means while our population estimates are not perfect, we can expect them to show differences between the Superblock estimates.
In our calculation, we do not need a separate numerical uncertainty estimate, as the mathematical operations we do are only additive and multiplicative. For the cell area we do not add an uncertainty. Due to this choice, the final uncertainty estimate of each Superblocks aggregated population density has a standard deviation \(u(\rho_\mathrm{Superblock}) = \sqrt{\sum_{i=1}^N \left(\frac{u(p_i)}{A_i}\right)^2} = \frac{\rho_\mathrm{Superblock}\cdot \mathrm{MAPE}_\mathrm{urban}}{\sqrt{6}}\), where \(N\) is the number of cells in the Superblock and \(A_i\) is the area of the \(i\)-th cell.
Comparison with the Superblock population density#
To compare the two approaches, we will show the population densities in a scatter plot. We will calculate a fit with uncertainties to see the correlation between the two approaches. The expected result is a linear correlation with a slope of 1 if both approaches return the same population density. This is why we will use a linear fit. The fitting procedure will be a ODR (orthogonal distance regression) fit, as it is more robust than a simple linear regression and can handle uncertainties in both variables.
# ODR fit y= B[0] * x + B[1]
model_linear = Model(lambda B, x: B[0] * x + B[1])
mask = (lc_road_cells["pop_density_polygons"] > 0
) & (lc_road_cells["pop_density_sampled_10"] > 0)
data = RealData(lc_road_cells["pop_density_polygons"][mask],
lc_road_cells["pop_density_sampled_10"][mask],
sx=lc_road_cells["pop_density_polygons"][mask] * 0.218 * 6 ** 0.5,
sy=lc_road_cells["pop_density_sampled_10"][mask] * 0.218 * 6 ** 0.5)
odr_linear = ODR(data, model_linear, beta0=[1, 0])
output_linear = odr_linear.run()
# Plot the results
fig, ax = plt.subplots(figsize=(8, 6))
errorbars = ax.errorbar(x=data.x, y=data.y, xerr=data.sx, yerr=data.sy,
marker="", capsize=3, alpha=0.3, linestyle="")
x_fit = np.logspace(-6, -1, 200)
# Nominal fit
ax.plot(x_fit, output_linear.beta[0] * x_fit + output_linear.beta[1],
label=r"Linear Fit $\rho_\mathrm{sampled} = "
f"( {output_linear.beta[0]:.2f} \pm {output_linear.sd_beta[0]:.2f} ) "
r"\cdot \rho_\mathrm{polygons} + "
f"( {1e7 * output_linear.beta[1]:.2f} \pm "
f"{1e7 * output_linear.sd_beta[1]:.2f} ) \cdot 10^7$",
color="black")
# Uncertainty fit +-2 sigma
ax.plot(x_fit, (output_linear.beta[0] + 2 * output_linear.sd_beta[0]) * x_fit +
(output_linear.beta[1] + 2 * output_linear.sd_beta[1]),
color="black", linestyle="--")
ax.plot(x_fit, (output_linear.beta[0] - 2 * output_linear.sd_beta[0]) * x_fit +
(output_linear.beta[1] - 2 * output_linear.sd_beta[1]),
color="black", linestyle="--", label="95% Confidence Interval")
# Settings
ax.set_xscale("log")
ax.set_yscale("log")
ax.set_xlabel(r"Weighted Intersections $\rho_\mathrm{polygons}$ (people/m$^2$)")
ax.set_ylabel(r"Raster Stats $\rho_\mathrm{sampled}$ (people/m$^2$)")
ax.set_title("Comparison of Population Density (10m up-sampled)")
ax.legend()
ax.grid()
plt.show()
This shows both approaches are well proportional to each other. The 95% confidence interval looks narrow, while the scattered datapoints seem to have a large spread, but as there are many overlaying datapoints, the thin confidence interval reliably points out the proportionality. As the slope is a little above 1, we know the raster stats approach produces a slightly higher population densities. When we look at the comparison when not up-sampling, we see greater overestimation.
When looking closer into the differences of the two approaches, we can compare the relative differences
The average relative difference is around \(\pm 2 \times 10^{-1} \approx \pm 0 .2\%\). For smaller population densities, the relative difference is larger, but the absolute difference is smaller. Again, this effect might be visible for single cells, but when dissolving the cells into Superblocks, the effect will compensate itself.
We will settle for the second approach, as it is a cleaner approach, not needing the data up-sampling. This can be useful for large cities.
Implementation Usage#
The package has the function add_edge_population which adds the
edge attributes population, area and cell_id to the edges of a graph.
Furthermore, there is the function get_population_area which
you can pass a graph to summarize the population and area, respecting the edges with the
same geometry. Cells with the same geometry share the same cell, cell_id is used to
identify the cells. The function returns a tuple of the population and area. As for
many different Superblock configurations we want to calculate the population density,
add_edge_population is called when loading the graph the first
time, so this preprocessing step is only done once.
To demonstrate the implemented functions we will use a new place. This time the 11th District in Kandahar, Afghanistan. The District is called یولسمه ناحیه. Kandahar is the second largest city in Afghanistan after Kabul[5].
kd_graph = ox.graph_from_place("11th District, Kandahar, Kandahar Province, "
"Afghanistan", network_type="drive")
kd_graph = ox.project_graph(kd_graph)
# Add population to the edges
add_edge_population(kd_graph)
# Make up subgraph to calculate the population for
kd_subgraph = ego_graph(kd_graph, list(kd_graph.nodes())[0], radius=15, undirected=True)
# Get population and area
get_population_area(kd_subgraph) # returns population (people) and area (m^2)
Returning the population and area of the subgraph, dividing both gives the population density of the subgraph.
To visualize this, we could plot it using the edges, but as the other plots were also with edge cells, let’s add them.
add_edge_cells(kd_graph)
kd_edges = ox.graph_to_gdfs(kd_graph, nodes=False, edges=True)
kd_subgraph_edges = ox.graph_to_gdfs(kd_subgraph, nodes=False, edges=True)
# Add cell geometry to the subgraph edges
kd_subgraph_edges["cell_geometry"] = kd_subgraph_edges.apply(
lambda x: kd_edges.loc[x.name, "cell"], axis=1)
kd_edges.set_geometry("cell", inplace=True)
kd_subgraph_edges.set_geometry("cell_geometry", inplace=True)
axe = kd_edges.plot(figsize=(8, 8), column="population", legend=True,
cmap="viridis", alpha=0.6, edgecolor="white")
kd_subgraph_edges.dissolve().plot(ax=axe, color="none", edgecolor="blue",
linewidth=2)
plt.show()
- superblockify.population.approximation.add_edge_population(graph, overwrite=False, **tess_kwargs)[source]
Add edge population to edge attributes in the graph.
Calculates the population and area of the edges. First tessellates the edges and then determines the population with GHSL data. Function writes to edge attributes population and area of the graph in-place. Furthermore, cell_id is added to the edge attributes, for easier summary of statistics later. The graph attribute edge_population is set to True. With this information, population densities can be calculated for arbitrary subsets of edges.
- Parameters:
- graphnetworkx.MultiDiGraph
The graph to tessellate.
- overwritebool, optional
If True, overwrite existing population and area attributes. Only depends on the graph attribute edge_population and not on the actual attributes.
- **tess_kwargs
Keyword arguments for the
superblockify.population.tessellation.get_edge_cells()function.
- Raises:
- ValueError
If the graph already has population and area attributes and overwrite is False.
- ValueError
If the graph is not in a projected coordinate system.
- ValueError
If the limit and the edge points are disjoint.
Notes
The graph must be in a projected coordinate system.
- superblockify.population.approximation.get_population_area(graph)[source]
Calculate the population of a graph or subgraph.
Calculates the population and area of the graph.
- Parameters:
- graphnetworkx.MultiDiGraph
Graph or subgraph. Must have edge attributes population, area and cell_id.
- Returns:
- populationfloat
Population of the subgraph.
- areafloat
Area of the subgraph.
- Raises:
- ValueError
If the graph does not have the population attributes.